
In research, complex models and advanced statistical techniques often get the spotlight. But here’s the truth: if data is dirty, results are wrong—no matter how advanced the analysis looks.
Data cleaning is not optional. It is the backbone of research integrity, transforming raw inputs into credible evidence. Neglecting it risks misleading findings, wasted resources, and lost trust.
Why Data Cleaning Is Essential
Data cleaning is not just a technical step—it is an ethical responsibility. A poorly prepared dataset can distort entire fields of knowledge, especially in health, education, climate, and economics research.
Key Issues Researchers Often Overlook
1. Missing Data Mismanagement
- Simply deleting missing cases reduces sample size and weakens statistical power.
- Patterns of missingness—MCAR (Missing Completely at Random), MAR (Missing at Random), and MNAR (Missing Not at Random)—require specific approaches.
- Methods such as multiple imputation and maximum likelihood estimation provide more accurate solutions (Little & Rubin, 2019).
2. Outliers Overlooked
- Outliers can distort regression coefficients and inflate errors.
- Not all outliers are errors—some reflect rare but meaningful phenomena.
- Tools like boxplots, Cook’s Distance, and Mahalanobis Distance help detect and interpret them.
3. Coding & Entry Errors
- A single mis-coded entry (e.g., “55” instead of “5”) can create false patterns.
- Frequency tables and logic rules reduce unnoticed mistakes.
- Automated validation checks during data entry prevent costly errors later.
4. Inconsistent Scales and Units
- Mixing USD with local currency or centimeters with inches produces invalid comparisons.
- Inconsistent Likert scales (0–4 vs. 1–5) destroy comparability.
- Standardization before analysis is crucial for reliability.
Why This Matters
- Misleading Evidence – Dirty data produces confident but wrong results.
- Peer Review Failures – Reviewers flag inconsistencies, leading to rejection.
- Policy Risks – Decisions based on flawed data waste resources.
- Lost Trust – Funders, stakeholders, and readers lose confidence.
How We Help at Research & Report Consulting
At Research & Report Consulting, we integrate systematic data cleaning into every research pipeline:
- Missing Data Handling – Detecting patterns, applying imputation, or robust methods.
- Outlier Detection – Statistical diagnostics and domain expertise for proper treatment.
- Coding Validation – Frequency checks, cross-tabulations, and automated logic rules.
- Consistency Checks – Standardizing units, scales, and codes.
- Transparent Documentation – Every step recorded for reproducibility.
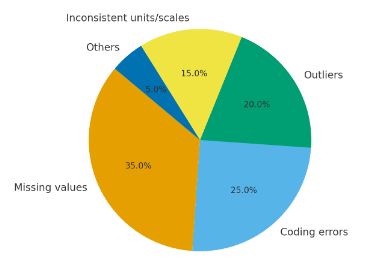
Figure: Common sources of dirty data, Source: Based on IBM Data Quality Study, 2021
Final Thought
Clean data is the foundation of credible evidence. Sophisticated models built on dirty inputs are nothing more than illusions of rigor.
At Research & Report Consulting, we help scholars, NGOs, and institutions design research pipelines that begin with rigorous data cleaning. Because in research, rigor starts before analysis—not after.
Question for Readers:
How do you currently handle data cleaning in your research projects—and what challenges do you face?