
In research, content analysis is one of the most powerful methods for decoding meaning from text, media, or communication. Yet many studies collapse under one silent flaw — poor intercoder reliability (ICR). Most researchers assume that once coders agree “most of the time,” their analysis is valid. Unfortunately, that’s a misconception. True intercoder reliability is not about casual agreement — it’s about statistical consistency. Without it, even a well-designed coding framework can produce biased or misleading results.
The Hidden Flaw in Many Content Analyses
Researchers may design robust surveys, collect rich qualitative data and craft smart codebooks — yet fail at one critical step: ensuring that different coders interpret and apply the codes in the same way. The result? Divergent coding, undocumented biases and findings that cannot be replicated or trusted. In the era of journal scrutiny and meta-studies, ICR is increasingly a required mark of methodological rigor. PMC
What Is Intercoder Reliability?
Defining the Concept
Intercoder reliability refers to the extent to which two or more coders assign the same codes to the same units of content (text, media, communication) in a consistent way. Illinois Open Publishing
It is a measure of consistency and replicability in content analysis.
How It Differs From Simple Agreement
Raw agreement (e.g., “coder A agreed with coder B 85% of the time”) is easy to report — but it doesn’t account for chance agreement, nor does it guarantee that the coding scheme is applied reliably. The use of chance-corrected metrics (such as Cohen’s Kappa, Krippendorff’s Alpha, Scott’s Pi) helps ensure a more accurate reliability assessment. ATLAS
Five Common Issues That Undermine ICR
Here are the most critical issues many researchers don’t sufficiently address:
Subjective Interpretation Bias
Even when a codebook looks clear, coders may interpret text differently. Especially in qualitative categories, subtleties and individual judgement can lead to inconsistent coding. The lack of shared understanding undermines the reliability of findings.
Inconsistent Codebooks
If operational definitions are vague, overlapping or incomplete, coders will diverge in their application of codes. A robust codebook should include inclusion/exclusion criteria, examples, and clarity around edge cases.
Ignoring Statistical Indices
Many stop at reporting simple agreement percentages — a poor substitute for rigorous reliability checks. Chance-adjusted indices such as Cohen’s Kappa or Krippendorff’s Alpha reflect the true reliability of the coding process.
No Pilot Testing
Jumping straight into large-scale coding without a pilot reliability check is like driving a car without testing its brakes. Pilot testing with a sub-sample helps identify unclear definitions, coder drift and training gaps.
Poor Training or Calibration
Over time coders may drift from initial understanding. Without ongoing calibration sessions — where coders compare outcomes, resolve discrepancies, and re-align their interpretation — reliability can degrade.
Why It Matters – The Consequences of Low ICR
Lack of intercoder reliability invalidates your findings, undermines replicability, and weakens the credibility of your research. Many journals now require explicit ICR reporting as part of transparency and methodological rigor.
Here are key consequences:
- Biased outcomes — if different coders interpret differently, findings become coder-specific rather than data-driven.
- Poor comparability — subsequent researchers cannot replicate or compare your coding results reliably.
- Reduced trust — reviewers, funders and academic readers look for evidence that coding was consistent, rigorous and transparent.
- Inefficient scaling — without reliable coding among coders, dividing workload becomes risky and error-prone.
Best Practices for Achieving High Intercoder Reliability
Here’s a checklist to strengthen your coding process:
Develop a Clear Codebook
- Define each code with unambiguous criteria.
- Provide examples, counter-examples and edge-cases.
- Use an iterative process: draft → pilot → refine.
Conduct Pilot Reliability Checks
- Select a representative sub-sample of your data for pilot coding.
- Have multiple coders code the same units independently.
- Compute reliability indices; identify and resolve code discrepancies.
Compute and Report Appropriate Indices
- Choose metrics suited to your data (nominal vs ordinal, number of coders).
- Report actual scores (e.g., “Krippendorff’s Alpha = 0.82”).
- Explain thresholds and any remedial steps taken if reliability is low.
Ongoing Training & Calibration
- Schedule regular check-in sessions among coders.
- Discuss ambiguous cases, refine definitions.
- Monitor coder drift over time and recalibrate as needed.
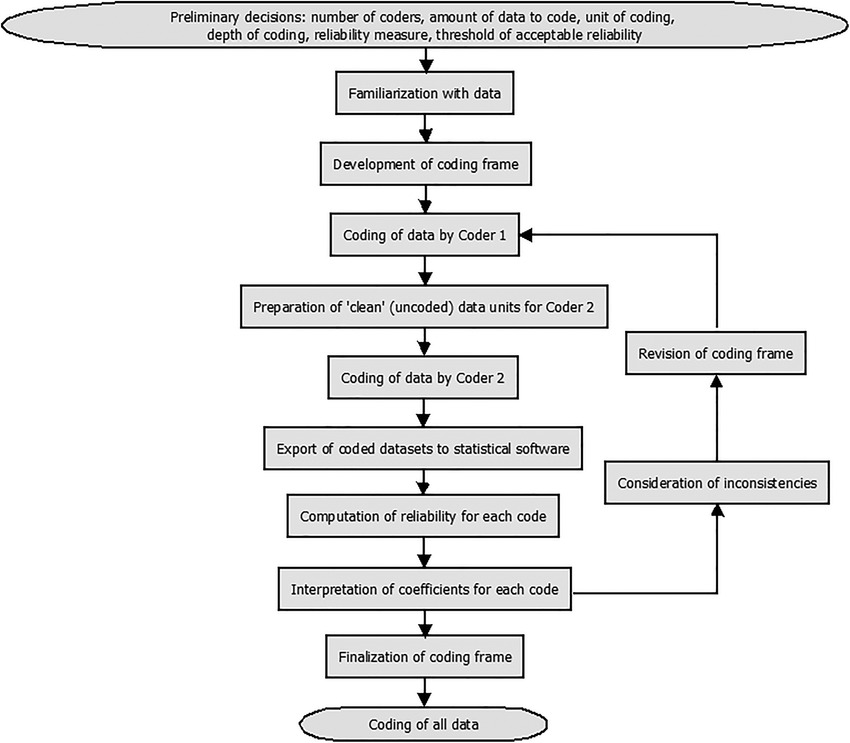
Figure: Suggested procedure for intercoder reliability assessment
Final Thoughts & Call to Action
High-quality content analysis hinges on one critical element: consistent, reliable coding across coders. Neglecting intercoder reliability doesn’t just weaken your paper — it undermines the entire research endeavour.
At Research & Report Consulting, we help researchers design measurable frameworks, conduct pilot reliability checks, compute indices, and build replicable protocols. Because reliable coding isn’t optional — it’s the foundation of valid content analysis.
Want research service from Research & Report experts? Please contact us.