
Why Big Data Isn’t Automatically Unbiased
In today’s research world, “big data” is often portrayed as objective, comprehensive and neutral. But the truth is different. Data sets are shaped by human decisions: what to include, what to exclude, how to categorise, what to prioritise.
When the assumptions baked into collection or algorithms go unexamined, bias creeps in. For example, the term “algorithmic bias” refers to systematic errors in machine-learning algorithms that produce unfair outcomes.
This means that even peer-reviewed studies may reflect, rather than correct, institutional or social biases.
Common Bias Sources in Big Data Pipelines
Data Blind Spots: Who Is Missing?
Many publicly available datasets ignore informal sectors, minority voices or developing regions. In healthcare AI research, one review noted that “several groups of the human population have a long history of being absent or misrepresented in existing biomedical datasets.” PMC
If under-represented populations are omitted, then results will not generalise and may reinforce inequities.
Training Data Bias & Model Inheritance
If the training set is skewed toward dominant groups, models will replicate those patterns. As one study puts it: “biased humans + incomplete data = algorithmic bias.” Accuray
The problem amplifies when models optimise for accuracy on majority data, ignoring minority subgroups.
Opaque Algorithms and Black-Box Models
Research often relies on algorithms that researchers cannot fully inspect. Lack of transparency (“black box” models) hides how decisions were made. The IBM article lists “biases in algorithmic design” and “biases in proxy data” as core causes.
Without auditability, bias creeps undetected into decisions.
Validation Gaps and Replicability Crisis
Few studies cross-validate algorithm outputs across diverse contexts. A systematic review noted that in public-health ML research most studies omit explicit subgroup analyses and fairness discussion. As a result, output may be “statistically sound” but socially skewed.
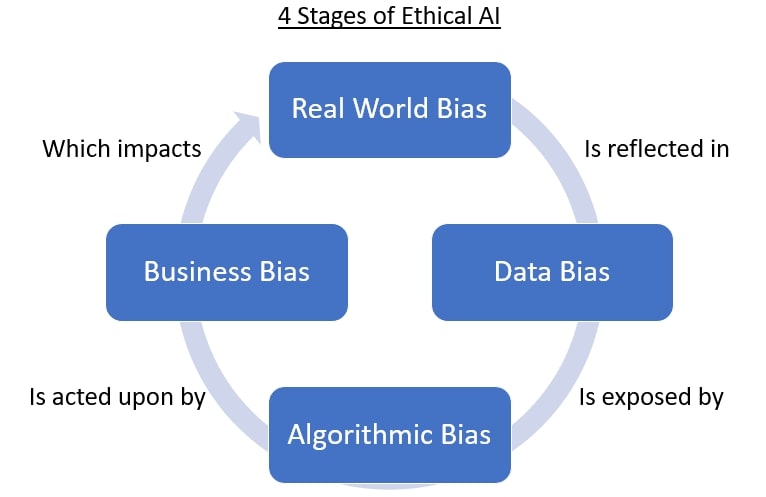
Figure: Four stages of Ethical AI
Real-World Impacts: When Bias Becomes Harm
- In recruitment, AI-enabled systems have been found to perpetuate discrimination by gender, race or personality traits. Nature
- In healthcare, algorithms trained on non-representative data misdiagnose or under-serve minority groups. PMC
- On the ethics front, the report from the Greenlining Institute argues automated systems often codify the past instead of improving the future. The Greenlining Institute
- These issues show that if research aims to drive equitable evidence-based policy, hidden biases must be exposed and corrected.
How Scholar-Consulting Can Help Correct the Course
At Research & Report Consulting we support scholars and institutions to identify hidden algorithmic distortions, improve data validity and ensure findings reflect real-world complexity — not machine bias.
Key Areas of Support
- Transparent data pipelines: We map end-to-end flow of data — from collection, cleaning, modelling to interpretation.
- Ethical algorithm audits: We apply fairness frameworks and metrics to detect imbalances in model outcomes.
- Cross-context validation: We test results across different sub-populations and settings to avoid single-group over-fitting.
- Inclusive variable design: We help define categories and variables so under-represented groups are captured.
- Documentation and reproducibility: We support clear metadata, open-code practices and replication protocols.
Practical Steps for Research Teams & Institutions
- Include diverse populations in the data collection stage.
- Monitor representation of key demographic variables (race, gender, region, socioeconomic status).
- Evaluate algorithmic choices for proxy variables and design weightings.
- Transparently document each stage of the pipeline (data, algorithm, validation).
- Conduct subgroup analyses and fairness checks (e.g., outcome differences by group).
- Publish data dictionary, algorithmic decisions and audit logs whenever possible.
- Adopt external reviews or algorithm-audit partners for high-stakes models.
- Make replication easy — share code, data (when ethics allow) and methodological detail.
Conclusion – Why It Matters
Research in the age of big data carries great promise for insight and impact. But that promise comes with responsibility. If algorithms replicate bias—data blind spots, narrow training sets, opaque design, weak validation—then research may inadvertently continue inequality instead of revealing or reducing it.
To build evidence-based policy that truly serves all populations, researchers must treat algorithms and datasets not as magically neutral tools, but as human-shaped systems requiring audit, correction and transparency.
How will your next research project ensure that algorithmic bias is not quietly shaping the results?
References
- What is algorithmic bias? IBM Think.
- N. Norori et al., “Addressing bias in big data and AI for health care,” PMC, 2021.
- Z. Chen, “Ethics and discrimination in artificial intelligence-enabled recruitment practices,” Humanities & Soc Sciences Communications, 2023.
- Greenlining Institute, “Algorithmic Bias Explained.
- K. Ukanwa, “Algorithmic bias: Social science research integration,” ScienceDirect, 2024.
- S. Akter et al., “Algorithmic bias in data-driven innovation in the age of AI,” NSF, 2021.
- Article on “Big data ethics” (Wikipedia) – overview of ethical implications.
Want research service from Research & Report experts? Please contact us.